Evaluating artifact#
Evidence of bug finding#
In our paper, we claimed that (in the abstract):
… has found 65 new bugs in the last seven months for TVM, TensorRT, ONNXRuntime, and PyTorch.
You can find the evidence in our bug finding table.
Coverage experiments#
We will go through the main experiments corresponding to Section 5.2 in the paper, which evaluates end-to-end coverage efficiency of NNSmith and baselines.
Expected time cost
21hours machine time;<1hour human time;
Experiment ID |
NNSmith[1] |
GraphFuzzer[2] |
LEMON[3] |
|---|---|---|---|
TVM |
E1 (4hr) |
E2 (5hr) |
E3 (2hr) |
ONNXRuntime |
E1 (4hr) |
E2 (5hr) |
E3 (1hr) |
Note
We call ONNXRuntime as “ort” for short.
TL;DR#
Evaluate the artifact in the fastest way:
Just run this in a tmux session;
Script
bash /artifact/eval_nnsmith.sh; \
bash /artifact/eval_graphfuzzer.sh; \
bash /artifact/eval_lemon.sh
Come back 1 day later;
Jump to the result visualization section to verify the results.
Or if you want to understand the scripts being executed, you can continue reading the following sub-sections (E1~E3).
E1: NNSmith[1] Coverage#
E1: Evaluating NNSmith on {tvm, ort}
Fuzzer type: NNSmith (with binning);
System under test (SUT):
TVM (LLVM CPU backend);
ONNXRuntime (CPU backend);
Experiment time: 8 hours;
Outputs (will be used in visualization section):
/artifact/nnsmith/nnsmith-tvm-binning//artifact/nnsmith/nnsmith-ort-binning/
Script
cd /artifact # In the container
bash eval_nnsmith.sh
E2: GraphFuzzer[2] Coverage#
“GraphFuzzer” (..huh?)
The paper by Luo, Weisi, et al[2] does not give a name to the fuzzer. We call it “GraphFuzzer” for convenience.
E2: Evaluating GraphFuzzer on {tvm, ort}
Fuzzer type: GraphFuzzer;
System under test (SUT):
TVM (LLVM CPU backend);
ONNXRuntime (CPU backend);
Experiment time: 10 hours;
Outputs (will be used in visualization section):
/artifact/nnsmith/graphfuzzer-tvm//artifact/nnsmith/graphfuzzer-ort/
Script
cd /artifact # In the container
bash eval_graphfuzzer.sh
E3: LEMON[3] Coverage#
E3: Evaluate LEMON on {tvm, ort}
Pre-generated LEMON models
Evaluating LEMON in NNSmith’s setting is very complicated (why?).
For reviewers’ convenience, the LEMON models are pre-generated and pre-converted (see -v /data/artifact:/... in the docker run command).
Nevertheless, you can refer to Generate LEMON models from scratch to re-generate the models.
Fuzzer type: LEMON;
System under test (SUT):
TVM (LLVM CPU backend);
ONNXRuntime (CPU backend);
Experiment time: 3 hours;
Outputs (will be used in visualization section):
/artifact/nnsmith/lemon-tvm//artifact/nnsmith/lemon-ort/
Script
cd /artifact # In the container
bash eval_lemon.sh
Visualizing and understanding results#
Visualizing coverage
Run the following script to generate images in /artifact/nnsmith/tvm-cov and /artifact/nnsmith/ort-cov.
bash /artifact/viz_main.sh
# Check the outputs.
$ ls /artifact/nnsmith/tvm-cov
# tvm_br_cov_venn.png tvm_branch_cov-time.png tvm_opt_branch_cov-iter.png
# tvm_branch_cov-iter.png tvm_opt_br_cov_venn.png tvm_opt_branch_cov-time.png
$ ls /artifact/nnsmith/ort-cov/
# ort_br_cov_venn.png ort_branch_cov-time.png ort_opt_branch_cov-iter.png
# ort_branch_cov-iter.png ort_opt_br_cov_venn.png ort_opt_branch_cov-time.png
Check the results
The image results are still in the docker container, we need pull those images out of it to see how they look like.
Get image outputs from docker to local
First you need to temporarily leave the current container, there are three ways to do it:
TMUX:
ctr + bthend;Local (recommended): just open a new terminal on the machine which is by default out of the container;
Local: type
exitto exit the container environment (later you can resume the container withdocker start -i ${USER}-nnsmith);
# Now in the local environment
docker cp ${USER}-nnsmith:/artifact/nnsmith/tvm-cov . # copy TVM results to local folder `tvm-cov`
docker cp ${USER}-nnsmith:/artifact/nnsmith/ort-cov . # copy ORT results to local folder `ort-cov`
Now let’s check the results corresponding to figures in the paper:
Fuzzing randomness
The sample images below are freshly generated when testing the artifact on the original test-bed (Oct. 14, 2022). They can slightly differ from that in the paper due to fuzzing randomness.
The randomness in fuzzing could come from performance divergence in different system and random seeds. This means detailed reproduced data might not be strictly equivalent to that presented in the paper, but the overall trend should be consistent in the long run (say 4 hours).
Potential legend style shifting (if you skipped LEMON)
According to E3: LEMON3 Coverage, the curve/pie for LEMON baseline might not be available if not starting with the original test-bed). As a result, showing only two baselines make the curves or pies of the figures below shifted with legend styles. In this case, please distinguish the systems by tagged labels as the colors might not match that in the original paper.
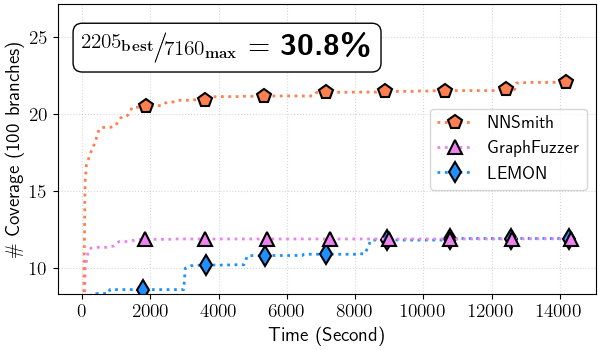
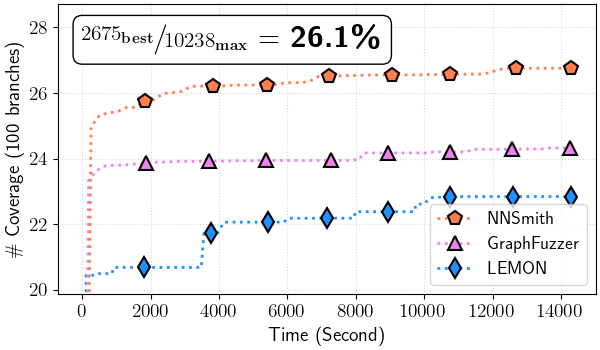
Figure 4: Total branch coverage over time (all files)
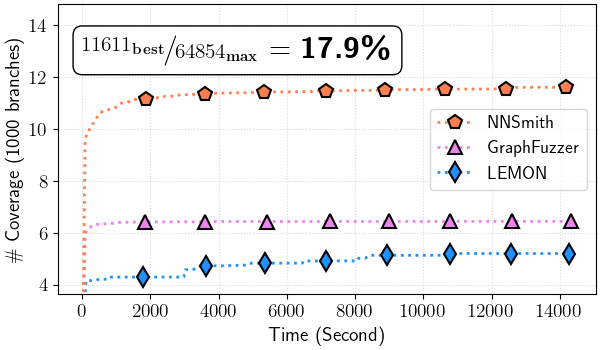
Figure 4.(a) ONNXRuntime
In ./ort-cov/ort_branch_cov-time.png#
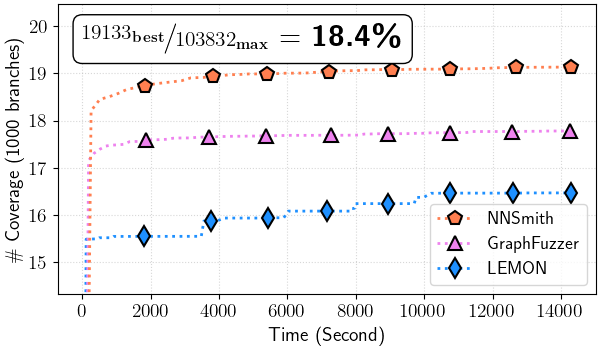
Figure 4.(b) TVM
In ./tvm-cov/tvm_branch_cov-time.png#
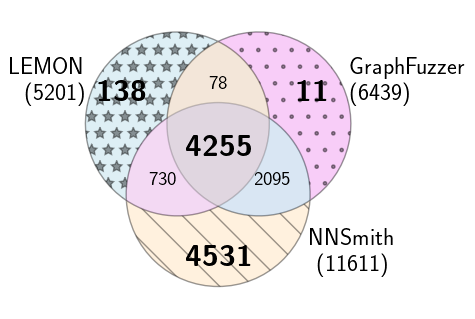
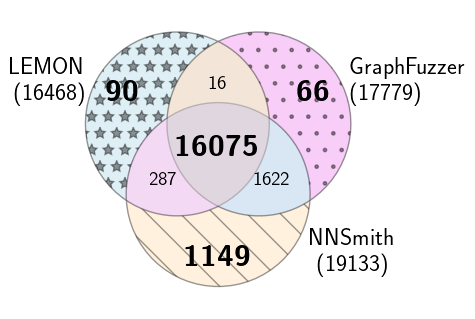
Figure 5: Total branch coverage over test cases (all files)
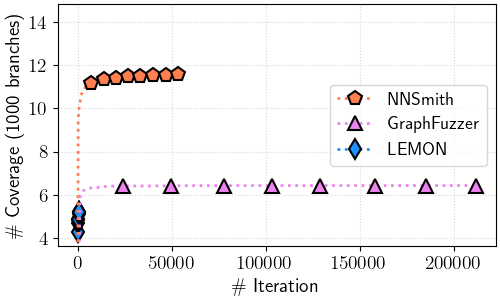
Figure 5.(a) ONNXRuntime
In ./ort-cov/ort_branch_cov-iter.png#
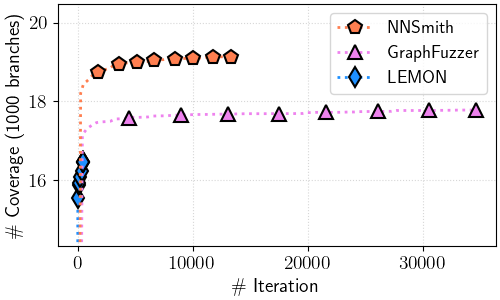
Figure 5.(b) TVM
In ./tvm-cov/tvm_branch_cov-iter.png#
Congratulations! You have successfully finished the main experiments of NNSmith!!! 🎉🎉🎉
Read more#
You may further refer to Read more for potential questions and extra/non-main experiments.